Spring 서비스의 Actuator 메트릭을 Prometheus에 연결하고, Grafana에서 조회하는 기본 연결을 구성해봤다. 이 글은 연결 과정과 함께, 이후 확장할 수 있는 메트릭·대시보드·알림 활용 방법을 정리한다.
1. 도입 배경
서비스 상태를 로그만으로 확인하면 메모리 사용량, HTTP 지연, 커넥션 풀 상태처럼 시간에 따라 변하는 값을 한눈에 보기 어렵다. Prometheus와 Grafana는 이런 메트릭 기반 관측을 시작할 때 널리 쓰이는 조합이다.
이 문서에서는 Spring Boot Actuator와 Prometheus, Grafana를 연결하는 기본 구성을 다룬다. 이후 OOM 분석, 대시보드 구성, 알림 등은 이 연결을 바탕으로 적용할 수 있는 확장 방법으로 소개한다.
세 툴의 역할은 이렇게 나뉜다.
- Prometheus — 메트릭을 주기적으로 수집(scrape)하고 시계열로 저장한다. Spring Boot Actuator가
/actuator/prometheus로 메트릭을 그대로 뱉어주기 때문에 쉽게 적용할수 있다. - Grafana — Prometheus에 쌓인 데이터를 대시보드로 시각화한다. 잘 만들어진 대시보드를 ID만으로 가져다 쓸 수 있어서 처음 세팅 비용이 적다.
- cAdvisor — 컨테이너 단위로 메모리/CPU/네트워크, 그리고 OOM 발생을 수집할 수 있다. 앱 내부(JVM)가 아니라 컨테이너 바깥에서 본 리소스다. macOS(Colima/Docker Desktop)에서는 컨테이너별 메트릭이 제한될 수 있어 JVM 힙 메트릭이나
docker stats를 함께 확인할 수 있다.
정리하면 앱 메트릭은 Actuator → Prometheus, 컨테이너 메트릭은 cAdvisor → Prometheus, 그리고 둘 다 Grafana로 시각화하는 구조다. 연결 후에는 JVM 힙, HTTP 지연, 커넥션 풀 등 필요한 메트릭을 선택해 볼 수 있다.
2. 전체 구조
[Spring 서비스들] [컨테이너 런타임]
/actuator/prometheus cAdvisor
│ │
│ (30s 주기 scrape) │
▼ ▼
┌─────────────────────────────────┐
│ Prometheus │ 메트릭 수집/저장 (TSDB, 7일 보관)
└────────────────┬────────────────┘
│ (PromQL 쿼리)
▼
┌─────────────────────────────────┐
│ Grafana │ 대시보드 시각화
└─────────────────────────────────┘
아래는 컨테이너로 구성할 수 있는 예시다.
| 컨테이너 | 이미지 | 노출 | mem_limit | 역할 |
|---|---|---|---|---|
| prometheus | prom/prometheus:v3.1.0 | 127.0.0.1:3002 |
384M | 메트릭 수집/저장 (retention 7d) |
| grafana | grafana/grafana:11.4.0 | 127.0.0.1:3001 |
256M | 대시보드 |
| cadvisor | gcr.io/cadvisor/cadvisor:v0.49.1 | 미노출 | 192M | 컨테이너 메모리/CPU/OOM |
표의 노출 포트(3001, 3002)는 각 툴의 기본 포트가 아니다. 내 환경에서는 다른 개발용 프로세스가 이미 기본 포트를 쓰고 있어서 호스트 쪽 포트만 비켜 매핑한 것이고, 컨테이너 내부는 기본 포트를 그대로 쓴다(예: 127.0.0.1:3002:9090 — 호스트 3002 → 컨테이너 9090). 포트 충돌이 없다면 굳이 바꾸지 말고 기본 포트를 그대로 쓰는 편이 헷갈리지 않고 문서·대시보드와도 잘 맞는다. 각 툴의 기본 포트는 다음과 같다.
| 툴 | 기본 포트 |
|---|---|
| Prometheus | 9090 |
| Grafana | 3000 |
| cAdvisor | 8080 |
운영 환경에서는 외부에 새 포트를 불필요하게 열지 않아야 한다. Grafana와 Prometheus는 127.0.0.1로만 바인딩하고, 필요하면 SSH 터널로 접근할 수 있다. cAdvisor는 포트를 노출하지 않고 내부 네트워크에서 Prometheus가 수집하도록 구성할 수 있다.
3. 수집 대상
Prometheus는 prometheus.yml에 적힌 대상을 주기적으로 수집한다. 아래는 서비스, 게이트웨이, cAdvisor를 대상으로 한 구성 예시다.
- 도메인 서비스: 내부 네트워크로 각 서비스의 메트릭 엔드포인트를 수집할 수 있다.
/actuator/**는 외부 포트를 노출하지 않는 구성이 안전하다. - 게이트웨이: 외부 트래픽 포트와 전용 관리 포트를 분리해 actuator를 수집할 수 있다.
- cAdvisor: 컨테이너 단위 리소스.
# prometheus.yml
global:
scrape_interval: 30s
scrape_timeout: 10s
external_labels:
monitor: stock-msa
scrape_configs:
# 도메인 서비스 (내부 네트워크 직접 스크레이프)
- job_name: spring-domain
metrics_path: /actuator/prometheus
static_configs:
- targets:
- stock-corp:8081
- stock-finance:8082
- stock-price:8083
- stock-strategy:8084
- stock-ai:8085
- stock-auth:8086
- stock-trading:8087
labels:
tier: domain
# 인프라 서비스 (게이트웨이는 관리 포트 8090, 디스커버리는 8761)
- job_name: spring-infra
metrics_path: /actuator/prometheus
static_configs:
- targets:
- stock-gateway:8090
- stock-discovery:8761
labels:
tier: infra
# 컨테이너 리소스 — cAdvisor
- job_name: cadvisor
static_configs:
- targets:
- cadvisor:8080
labels:
tier: container
tier 라벨은 Grafana나 PromQL에서 도메인 서비스와 인프라 서비스를 나눠 볼 때 필터 기준으로 활용할 수 있다.
4. 연결 구성 예시
4.1 Spring 쪽 준비
각 서비스가 Prometheus 포맷으로 메트릭을 내보내려면 다음 의존성과 설정을 추가할 수 있다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
}
management:
endpoints:
web:
exposure:
include: health, info, prometheus
metrics:
tags:
application: ${spring.application.name} # 메트릭에 서비스 이름 태그 부여
게이트웨이는 다음처럼 관리 포트를 분리해 외부 트래픽 포트와 actuator를 구분할 수 있다.
# 게이트웨이 application.yaml
server:
port: 8080 # 외부 트래픽
management:
server:
port: 8090 # actuator 전용 (외부 비노출)
4.2 docker-compose에 스택 추가
prometheus:
image: prom/prometheus:v3.1.0
container_name: prometheus
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=7d
- --storage.tsdb.retention.size=2GB
- --web.enable-lifecycle
volumes:
- ./deploy/monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- prometheus-data:/prometheus
ports:
- "127.0.0.1:3002:9090" # localhost 바인딩
deploy:
resources:
limits:
memory: 384M
networks:
- stock-network
grafana:
image: grafana/grafana:11.4.0
container_name: grafana
environment:
- GF_SECURITY_ADMIN_USER=${GRAFANA_ADMIN_USER}
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_ADMIN_PASSWORD}
- GF_USERS_ALLOW_SIGN_UP=false
- GF_AUTH_ANONYMOUS_ENABLED=false
volumes:
- ./deploy/monitoring/grafana/provisioning:/etc/grafana/provisioning:ro
- grafana-data:/var/lib/grafana
ports:
- "127.0.0.1:3001:3000"
deploy:
resources:
limits:
memory: 256M
networks:
- stock-network
depends_on:
- prometheus
cadvisor:
image: gcr.io/cadvisor/cadvisor:v0.49.1
container_name: cadvisor
privileged: true
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
deploy:
resources:
limits:
memory: 192M
networks:
- stock-network
Grafana 관리자 비밀번호는 컴포즈에 직접 넣지 않고 .env의 GRAFANA_ADMIN_PASSWORD로 주입할 수 있다. 익명 접근과 회원가입을 막는 설정도 함께 검토한다.
4.3 Grafana 데이터소스 자동 등록
프로비저닝 파일을 두면 Grafana 컨테이너 기동 시 데이터소스를 자동 등록할 수 있다.
# grafana/provisioning/datasources/datasource.yml
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
isDefault: true
editable: false
4.4 실행
# .env 에 GRAFANA_ADMIN_PASSWORD 설정 후
docker compose up -d --build prometheus grafana cadvisor
- Grafana:
http://localhost:3001(admin /.env의 비밀번호) - Prometheus:
http://localhost:3002— 수집이 잘 되는지는 Status > Targets에서 각 타깃이UP인지로 확인한다.
4.5 대시보드 임포트
공개 대시보드는 Grafana 좌측 메뉴에서 ID로 가져와 사용할 수 있다. 데이터소스로 Prometheus를 선택하면 된다.
- 4701 — JVM (Micrometer): 힙/GC/스레드
- 19004 — Spring Boot 3.x Statistics: HTTP 요청/지연/DB 커넥션풀
- 14282 — cAdvisor: 컨테이너 메모리/CPU/네트워크
5. 연결 후 활용할 수 있는 방법
연결 후에는 메모리, HTTP 지연, 커넥션 풀처럼 필요한 메트릭을 PromQL과 Grafana로 확인할 수 있다. 아래는 적용 가능한 활용 사례와 쿼리 예시다.
5.1 메모리 / OOM 추적
배치나 대량 작업 중에는 어느 서비스의 힙이 차오르는지를 확인할 수 있다. JVM 힙과 컨테이너 메모리를 함께 보면 원인을 좁히는 데 도움이 된다.
- JVM(4701) — 서비스별 힙 사용률과 GC를 본다. 배치 중 특정 서비스 힙이 한도까지 차오르면 그 서비스가 위험 신호다. 서비스 구분은
instance라벨(stock-corp:8081등)로 된다.
# 서비스별 힙 사용률 (1에 가까울수록 위험)
jvm_memory_used_bytes{area="heap"} / jvm_memory_max_bytes{area="heap"}
# GC를 돌려도 줄지 않는 Old Gen (메모리 누수 신호)
jvm_memory_used_bytes{area="heap", id=~".*Old.*"}
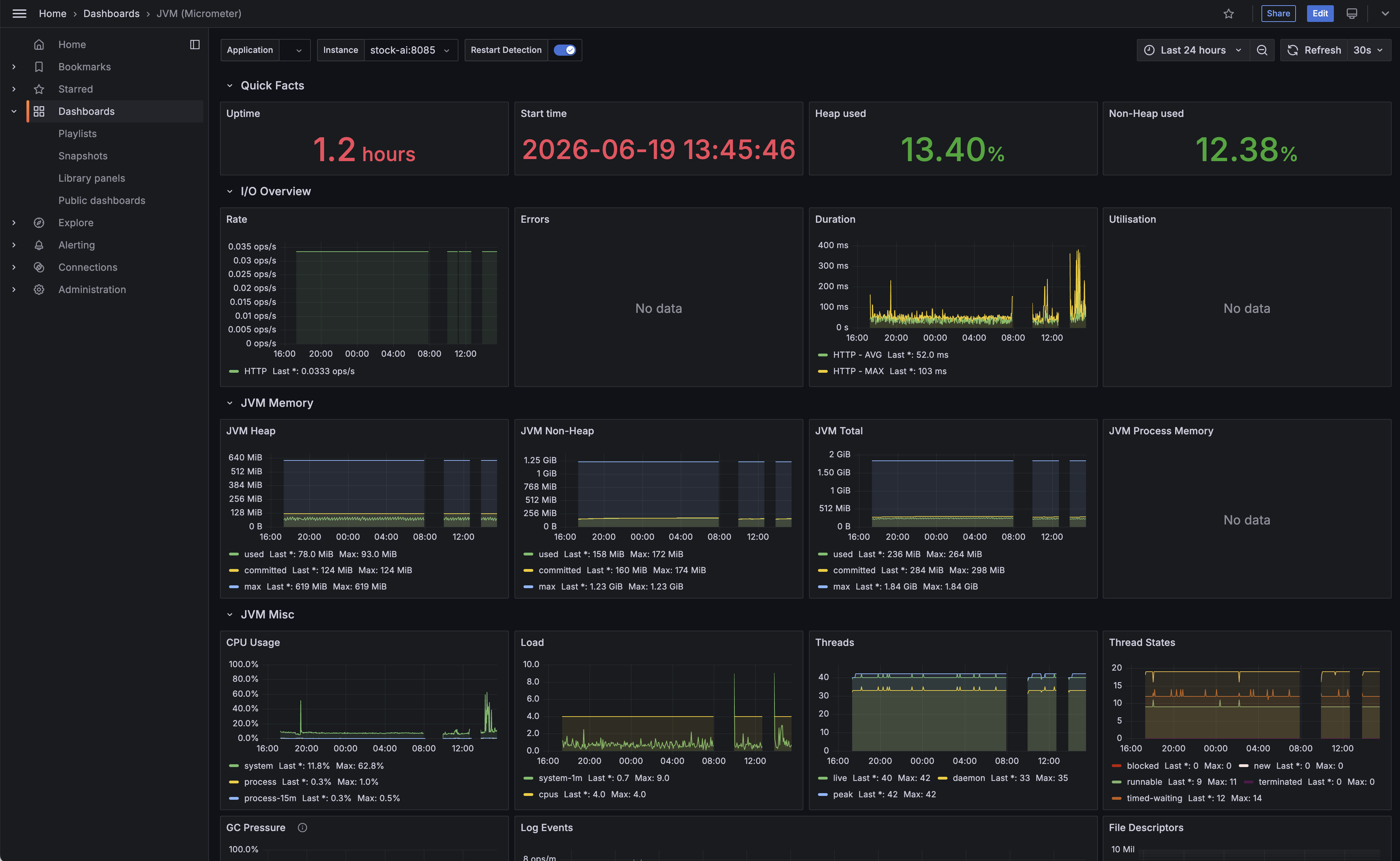 JVM(Micrometer, ID 4701) 대시보드 예시. 상단
JVM(Micrometer, ID 4701) 대시보드 예시. 상단 instance 드롭다운으로 서비스별 힙·Non-Heap 사용률, GC, 스레드를 확인할 수 있다.
docker stats— 컨테이너가 실제로mem_limit에 얼마나 근접했는지는 이게 제일 빠르다. 힙은 여유가 있는데 컨테이너 메모리만 튄다면 힙 밖(메타스페이스·다이렉트 버퍼·스레드 스택)을 의심한다.
docker stats --no-stream # 컨테이너별 메모리/CPU 즉석 확인
이 지표를 바탕으로 -Xmx와 컨테이너 mem_limit의 간격, 배치 청크 크기, 객체 생성량을 점검할 수 있다.
cAdvisor와 macOS 주의 — cAdvisor는 컨테이너 바깥에서 본 리소스를 수집할 수 있다. 다만 macOS의 Colima/Docker Desktop(Linux VM, cgroup v2)에서는 컨테이너별 메트릭이 제한될 수 있다. 이 경우 JVM 힙과
docker stats를 함께 확인하는 방법을 사용할 수 있다. 아래 쿼리는 Linux 호스트 환경에서 컨테이너별 메트릭을 확인할 때 활용할 수 있다.
# (Linux 호스트 기준) 컨테이너 메모리 — limit 대비 사용률
container_memory_working_set_bytes / container_spec_memory_limit_bytes
# OOM 발생 횟수
container_oom_events_total
5.2 에러율과 응답 지연 (HTTP)
배포 뒤 회귀나 특정 엔드포인트 지연을 확인할 때 활용할 수 있다.
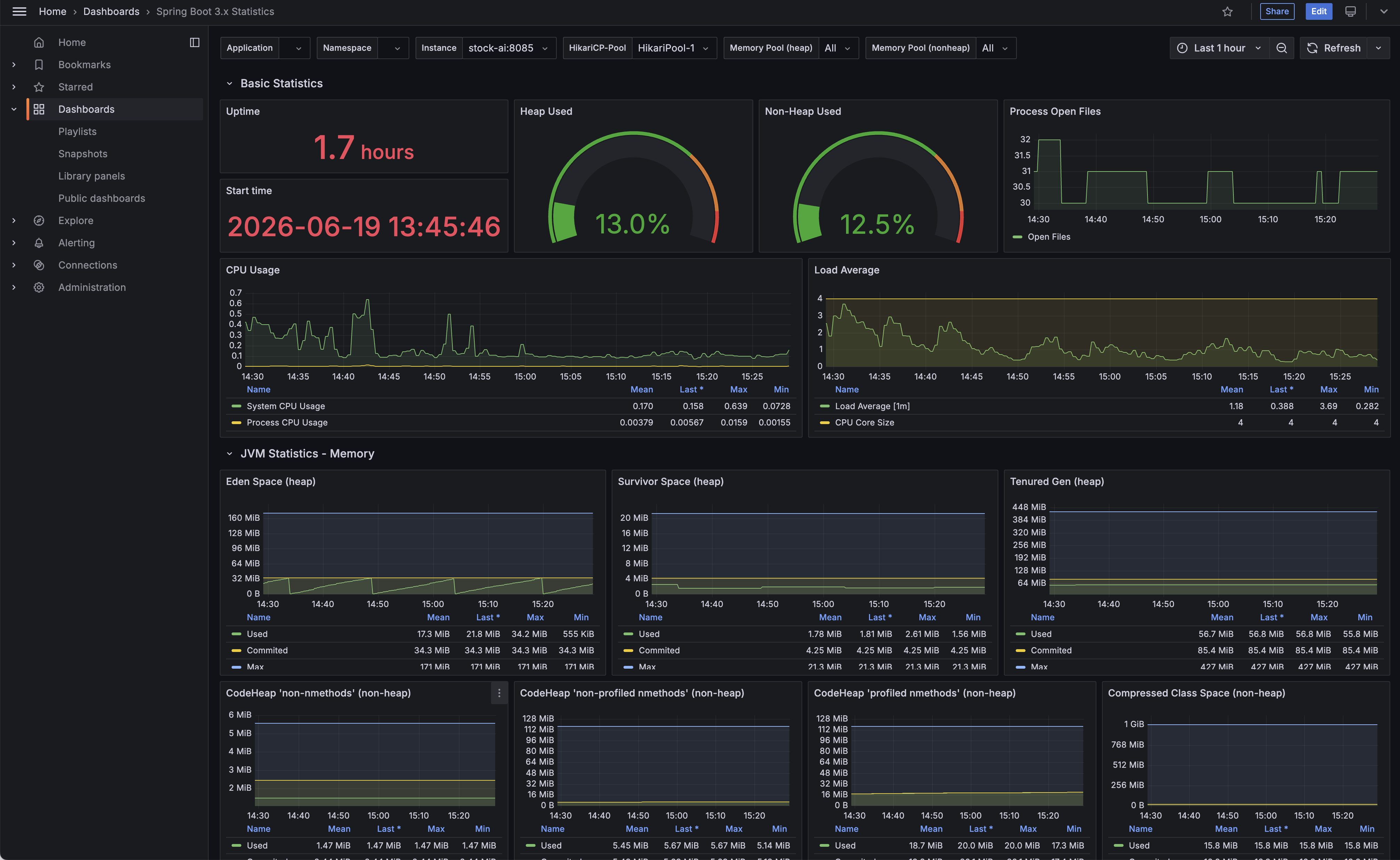 Spring Boot 3.x Statistics(ID 19004) 대시보드 예시. HTTP 요청·지연, HikariCP 커넥션 풀, 메모리를 한 화면에서 확인할 수 있다.
Spring Boot 3.x Statistics(ID 19004) 대시보드 예시. HTTP 요청·지연, HikariCP 커넥션 풀, 메모리를 한 화면에서 확인할 수 있다.
# 서비스별 5xx 비율 (배포 직후 튀면 회귀 의심)
sum(rate(http_server_requests_seconds_count{status=~"5.."}[5m])) by (job)
/ sum(rate(http_server_requests_seconds_count[5m])) by (job)
# 엔드포인트별 p99 지연 (특정 uri만 느리면 쿼리/락 의심)
histogram_quantile(0.99, sum(rate(http_server_requests_seconds_bucket[5m])) by (le, uri))
# 초당 요청 수(RPS) — 트래픽 급증/감소 탐지
sum(rate(http_server_requests_seconds_count[1m])) by (job)
분위수(p95/p99)는 히스토그램 버킷이 있어야 계산된다. 기본 HTTP 메트릭은
management.metrics.distribution.percentiles-histogram.http.server.requests=true로 켜준다.
5.3 DB 커넥션풀과 배치
배치가 DB를 오래 잡으면 다른 요청까지 커넥션을 못 받는다. 메모리 문제와 같이 보면 좋은 지표다.
# 커넥션풀 사용률 (1에 붙으면 풀 포화)
hikaricp_connections_active / hikaricp_connections_max
# 커넥션 획득 대기 (0보다 크게 쌓이면 풀 부족 또는 느린 쿼리)
hikaricp_connections_pending
# 커넥션 획득까지 걸린 시간 p99
histogram_quantile(0.99, sum(rate(hikaricp_connections_acquire_seconds_bucket[5m])) by (le))
Spring Batch 자체 진행 상황은 기본 메트릭으로 잘 안 나오므로, “몇 건 처리했는지” 같은 건 아래 5.5의 커스텀 메트릭으로 직접 노출하는 편이 낫다.
5.4 JVM 내부 (힙·GC·스레드)
# 힙 사용률
jvm_memory_used_bytes{area="heap"} / jvm_memory_max_bytes{area="heap"}
# GC에 쓴 시간 비율 (높으면 GC가 앱을 갉아먹는 중)
rate(jvm_gc_pause_seconds_sum[5m]) / rate(jvm_gc_pause_seconds_count[5m])
# 살아있는 스레드 수 (계속 늘면 스레드 풀 폭주/누수)
jvm_threads_live_threads
5.5 비즈니스 메트릭 직접 만들기
인프라 지표만으로는 주문 처리량이나 외부 API 지연 같은 도메인 관점을 파악하기 어렵다. Micrometer로 메트릭을 등록하면 비즈니스 지표도 Grafana에서 함께 볼 수 있다.
// 카운터: 배치가 처리한 건수
Counter processed = Counter.builder("batch.items.processed")
.tag("job", "priceSync")
.register(meterRegistry);
processed.increment(chunk.size());
// 타이머: 외부 API 호출 시간 (분위수 히스토그램 포함)
Timer.builder("external.api.latency")
.tag("api", "dart")
.publishPercentileHistogram()
.register(meterRegistry)
.record(() -> dartClient.fetch());
// 게이지: 현재 대기 큐 길이
meterRegistry.gauge("queue.pending", queue, Queue::size);
메서드에 @Timed("order.process")만 붙여도 타이머가 자동 등록된다. 등록한 메트릭은 이름이 Prometheus 규칙으로 바뀌어(batch.items.processed → batch_items_processed_total) 바로 쿼리할 수 있다.
# 분당 배치 처리 건수
rate(batch_items_processed_total[1m])
# 외부 API p95 응답시간 (api 라벨별)
histogram_quantile(0.95, sum(rate(external_api_latency_seconds_bucket[5m])) by (le, api))
# 현재 대기 큐 길이
queue_pending
5.6 Grafana 활용 방법
- 변수(Variable): 대시보드 상단에
$job드롭다운을 만들면 서비스를 골라가며 같은 패널을 볼 수 있다. 쿼리는label_values(http_server_requests_seconds_count, job). - 배포 어노테이션: 배포 시각을 그래프에 세로선으로 표시해두면, 지연·에러 급증이 “배포 직후 생긴 건지”를 한눈에 판단할 수 있다.
- Explore 탭: 대시보드를 만들기 전에 PromQL을 즉석에서 시험해볼 때 쓴다. 쓸 만한 쿼리는 패널로 저장한다.
5.7 알림(Alerting) 설정 예시
대시보드를 계속 확인할 수 없으므로 Grafana Alerting으로 알림 규칙을 설정할 수 있다. 아래 수치는 서비스 특성에 맞게 조정해야 하는 예시다.
| 상황 | 조건(예시) |
|---|---|
| OOM 임박 (내 핵심) | container_memory_working_set_bytes / container_spec_memory_limit_bytes > 0.9 5분 지속 |
| OOM 발생 | increase(container_oom_events_total[5m]) > 0 |
| 에러 급증 | 5xx 비율 > 1% |
| 힙 압박 | 힙 사용률 > 85% |
| 커넥션풀 부족 | hikaricp_connections_pending > 0 지속 |
알림 채널은 사내 메신저나 웹훅을 사용할 수 있으며, 인증 정보와 접근 제어를 함께 관리해야 한다.
5.8 타깃이 DOWN일 때
Prometheus Status > Targets에서 빨갛게 뜨는 job을 먼저 확인한다.
- 도메인 서비스가 DOWN: 컨테이너가 같은 네트워크에 있는지, 운영 프로파일에서
/actuator/prometheus가permitAll인지 확인한다. - 게이트웨이가 DOWN: 8080이 아니라 8090(관리 포트)을 긁고 있는지 본다.
management.server.port: 8090설정이 빠지면 메트릭이 안 나온다.
6. 리소스와 보관 주기 설정 시 고려할 점
모니터링 스택도 컨테이너 메모리와 디스크를 사용한다. 전체 서비스·DB·모니터링 컨테이너의 mem_limit 합계가 런타임의 가용 메모리를 넘지 않도록 계산해야 한다. 모니터링 컨테이너에도 리소스 상한을 두는 편이 안전하다.
데이터가 계속 쌓이는 곳은 사실상 Prometheus의 TSDB 하나다. 두 가지 보관 정책을 함께 걸어서, 둘 중 먼저 도달하는 조건이 트리거되게 했다.
--storage.tsdb.retention.time=7d: 7일 지난 데이터 삭제--storage.tsdb.retention.size=2GB: 디스크 2GB 초과 시 오래된 블록부터 삭제
cAdvisor가 컨테이너마다 시계열을 많이 만들기 때문에, 실질적인 안전장치는 용량(size) 쪽이다. 디스크가 빠듯하면 size를 줄이거나, cAdvisor job에 scrape_interval: 60s를 줘서 수집 빈도를 낮추면 된다.
7. 마치며
이 글에서는 Actuator → Prometheus → Grafana 연결 구조와, 이 연결 이후 적용할 수 있는 모니터링 방법을 정리했다. 현재 구성한 범위는 기본 연결이며, OOM 분석·알림·커스텀 메트릭·보관 주기 조정은 서비스 요구에 따라 추가할 수 있다.
운영 환경에서는 메트릭 엔드포인트의 외부 노출을 줄이고, 모니터링 컨테이너 자체의 리소스 상한과 보관 주기를 관리해야 한다. 이후 Loki 같은 로그 수집 도구나 Tempo·Zipkin 같은 분산 추적 도구를 연결하면, 메트릭 이상을 로그와 trace로 더 깊게 분석하는 흐름을 구성할 수 있다.